1. 概述
1.1 插件名称
- Logging-RabbitMQ Plugin
1.2 适用场景
- 通过rabbitmq收集网关http请求日志,通过其他应用消费rabbitmq消息,并且对日志进行分析。
1.3 插件功能
Apache ShenYu网关接收客户端请求,向服务端转发请求,并将服务端结果返回给客户端.网关可以记录下每次请求对应的详细信息,
列如: 请求时间、请求参数、请求路径、响应结果、响应状态码、耗时、上游IP、异常信息等待.
Logging-RabbitMQ插件便是记录访问日志并将访问日志发送到RabbitMQ集群的插件.
1.4 插件代码
-
核心模块
shenyu-plugin-logging-rabbitmq. -
核心类
org.apache.shenyu.plugin.logging.rabbitmq.LoggingRabbitmqPlugin -
核心类
org.apache.shenyu.plugin.logging.rabbitmq.client.RabbitmqLogCollectClient
1.5 添加自哪个shenyu版本
- ShenYu 2.5.0
1.6 技术方案
-
架构图
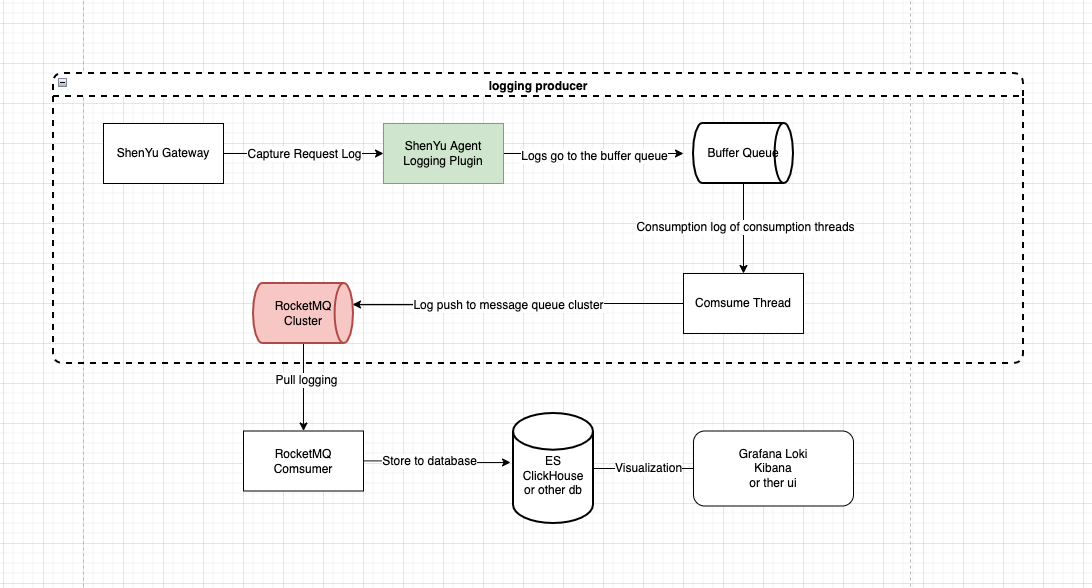
-
在
Apache ShenYu网关里面进行Logging全程异步采集、异步发送 -
日志平台通过消费
rabbitmq集群中的日志进行落库,再使用Grafana、Kibana或者其它可视化平台展示
2. 如何使用插件
2.1 插件使用流程图
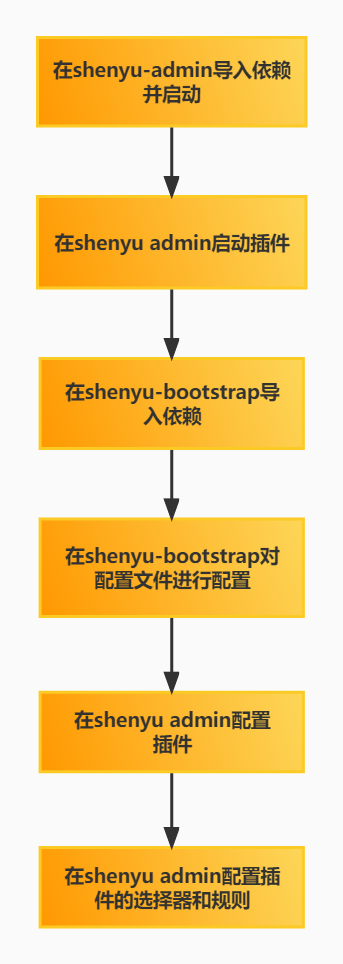
2.2 导入pom
- 在网关的
pom.xml文件中添加Logging-rabbitmq的依赖。
<!--shenyu logging-rabbitmq plugin start-->
<dependency>
<groupId>org.apache.shenyu</groupId>
<artifactId>shenyu-spring-boot-starter-plugin-logging-rabbitmq</artifactId>
<version>${project.version}</version>
</dependency>
<!--shenyu logging-rabbitmq plugin end-->
2.3 启用插件
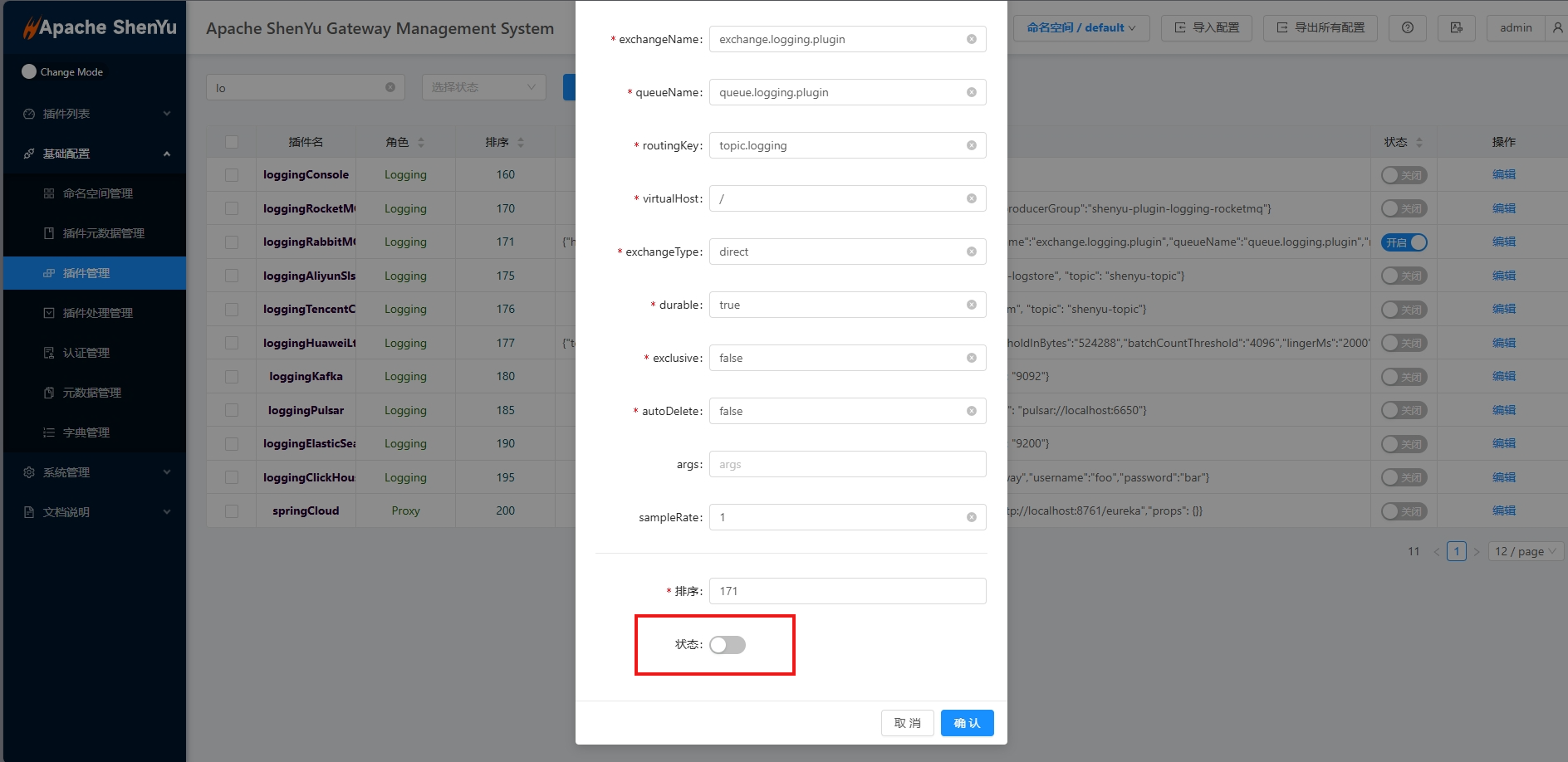
- 在
shenyu-admin--> 基础配置 --> 插件管理->loggingRabbitMQ,配置rabbitMQ参数,并设置为开启。
2.4 配置插件
2.4.1 开启插件,并配置rabbitmq,配置如下
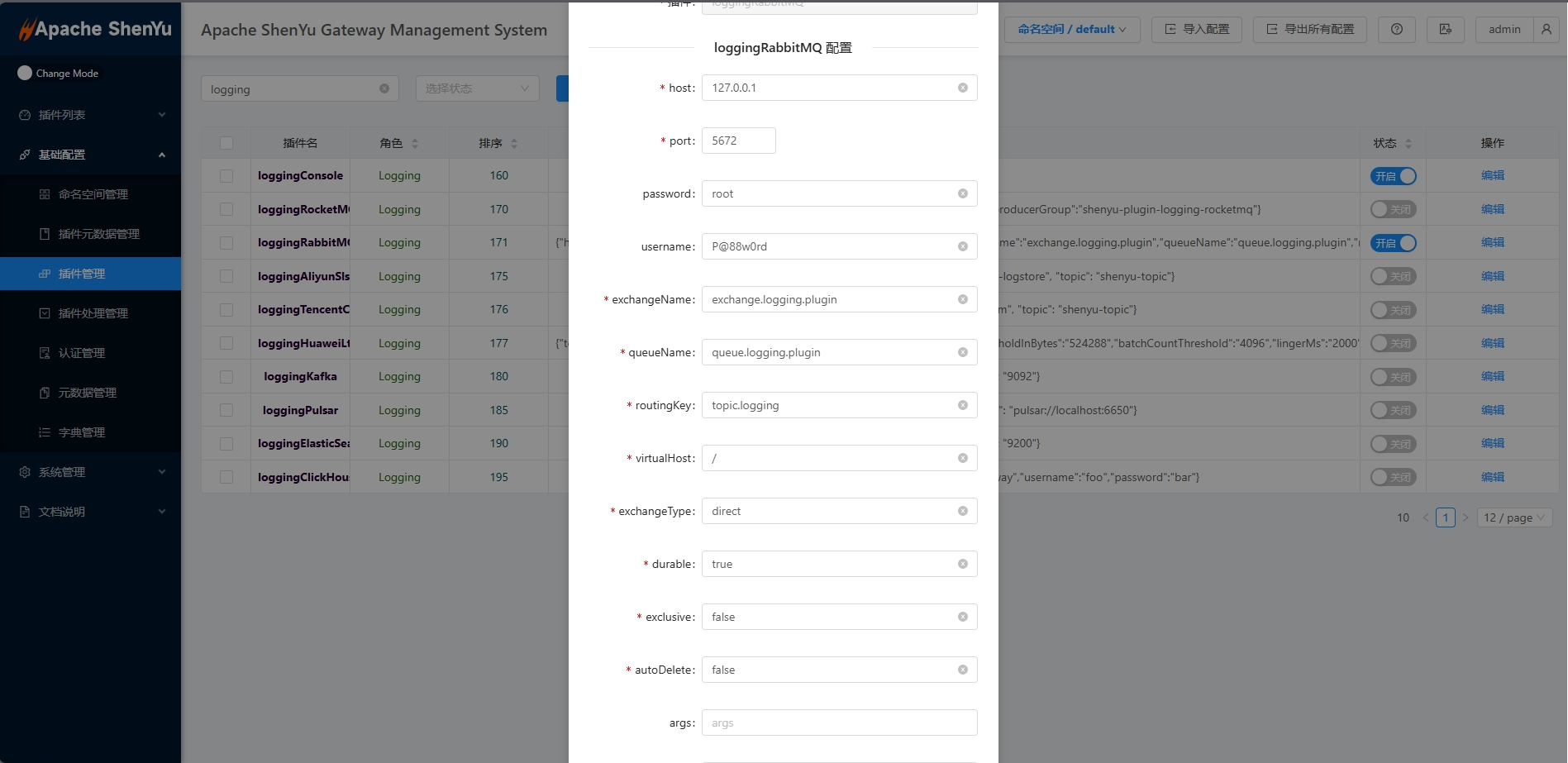
- 各个配置项说明如下:
| 配置项 | 类型 | 说明 | 备注 |
|---|---|---|---|
| host | type | IP | 必须 |
| port | type | 端口 | 必须 |
| username | String | 用户名 | 可选 |
| password | String | 密码 | 可选 |
| virtualHost | String | 虚拟主机 | 必须,默认/ |
| exchangeType | String | 交换机类型 | 必须,默认direct |
| exchangeName | String | 交换机名称 | 必须 |
| queueName | String | 队列名称 | 必须 |
| routingKey | String | 路由键 | 必须 |
| durable | Boolean | 持久化 | 必须,默认true |
| exclusive | Boolean | 是否为排他队列 | 必须,默认false |
| autoDelete | String | 自动删除 | 必须,默认false |
| args | String | rabbitmq参数,例如:{"x-delay":"1000"},表示延时队列,单位ms | 可选 |
| sampleRate | String | 采样率,范围0~1,0:关闭,0.01:采集1%,1:采集100% | 可选,默认1,全部采集 |
| maxResponseBody | Ingeter | 最大响应体大小,超过阈值将不采集响应体 | 可选,默认512KB |
| maxRequestBody | Ingeter | 最大请求体大小,超过阈值将不采集请求体 | 可选,默认512KB |
| 除了host,port,virtualHost,exchangeType,exchangeName,queueName,routingKey,durable,exclusive,autoDelete其它都是可选。 |
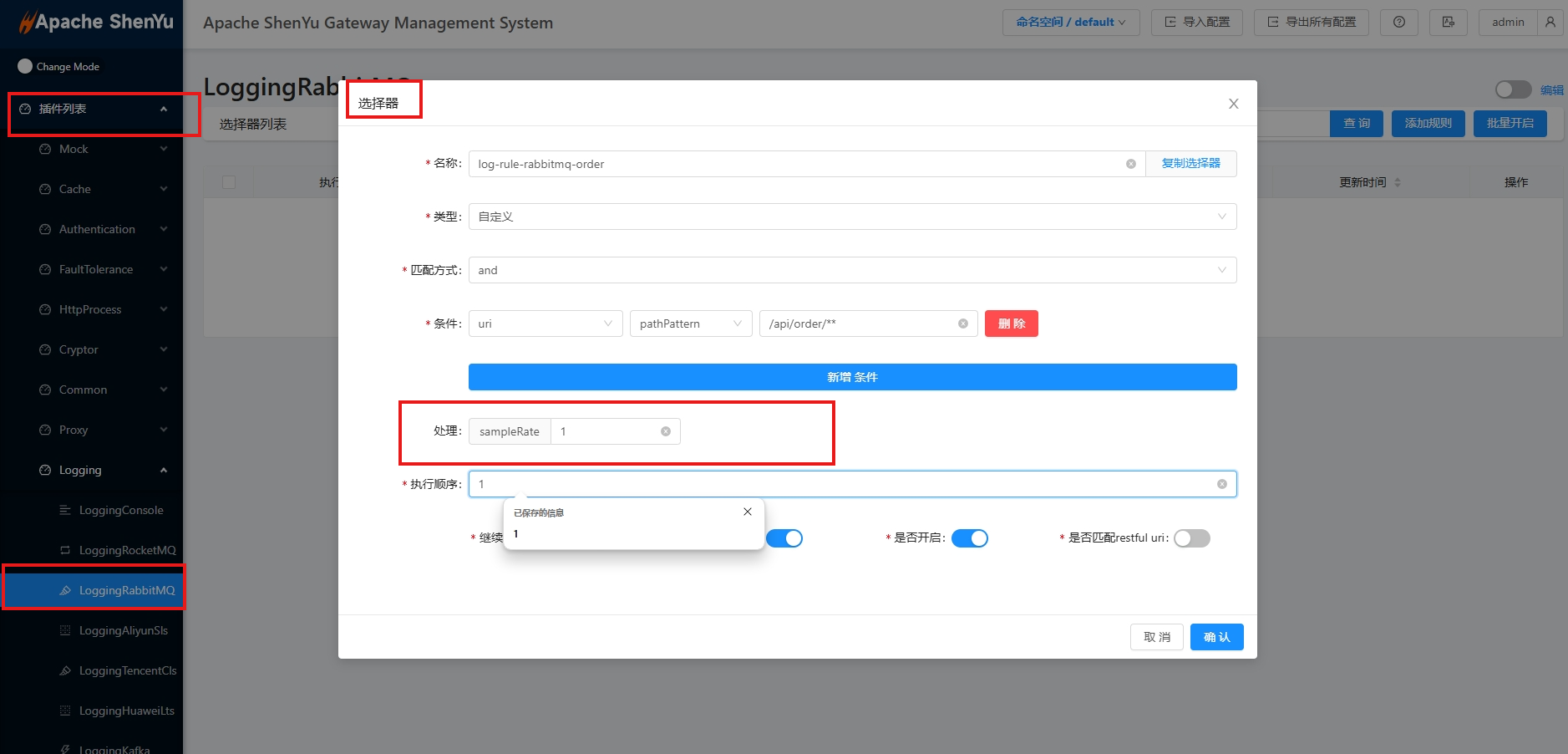
2.4.2 配置选择器和规则器
- 选择器和规则详细配置,请参考: 选择器和规则管理。
另外有时候一个大网关集群对应多个应用程序(业务),不同应用程序(业务)对应不同的主题,相关隔离,这时候可以按选择器配置不同的主题(可选)和采样率(可选),配置项的含义如上表所示。
操作如下图:
2.5 Logging信息
采集的access log的字段如下:
| 字段名称 | 含义 | 说明 | 备注 |
|---|---|---|---|
| clientIp | 客户端IP | ||
| timeLocal | 请求时间字符串, 格式:yyyy-MM-dd HH:mm:ss.SSS | ||
| method | 请求方法(不同rpc类型不一样,http类的为:get,post等待,rpc类的为接口名称) | ||
| requestHeader | 请求头(json格式) | ||
| responseHeader | 响应头(json格式) | ||
| queryParams | 请求查询参数 | ||
| requestBody | 请求Body(二进制类型的body不会采集) | ||
| requestUri | �请求uri | ||
| responseBody | 响应body | ||
| responseContentLength | 响应body大小 | ||
| rpcType | rpc类型 | ||
| status | 响应码 | ||
| upstreamIp | 上游(提供服务的程序)IP | ||
| upstreamResponseTime | 上游(提供服务的程序)响应请求的耗时(毫秒ms) | ||
| userAgent | 请求的用户代理 | ||
| host | 请求的host | ||
| module | 请求的模块 | ||
| path | 请求的路径path | ||
| traceId | 请求的链路追踪ID | 需要接入链路追踪插件,如skywalking,zipkin |
2.6 示例
2.6.1 通过RabbitMQ收集请求日志
2.6.1.1 插件配置
开启插件,并配置rabbitmq,配置如下:
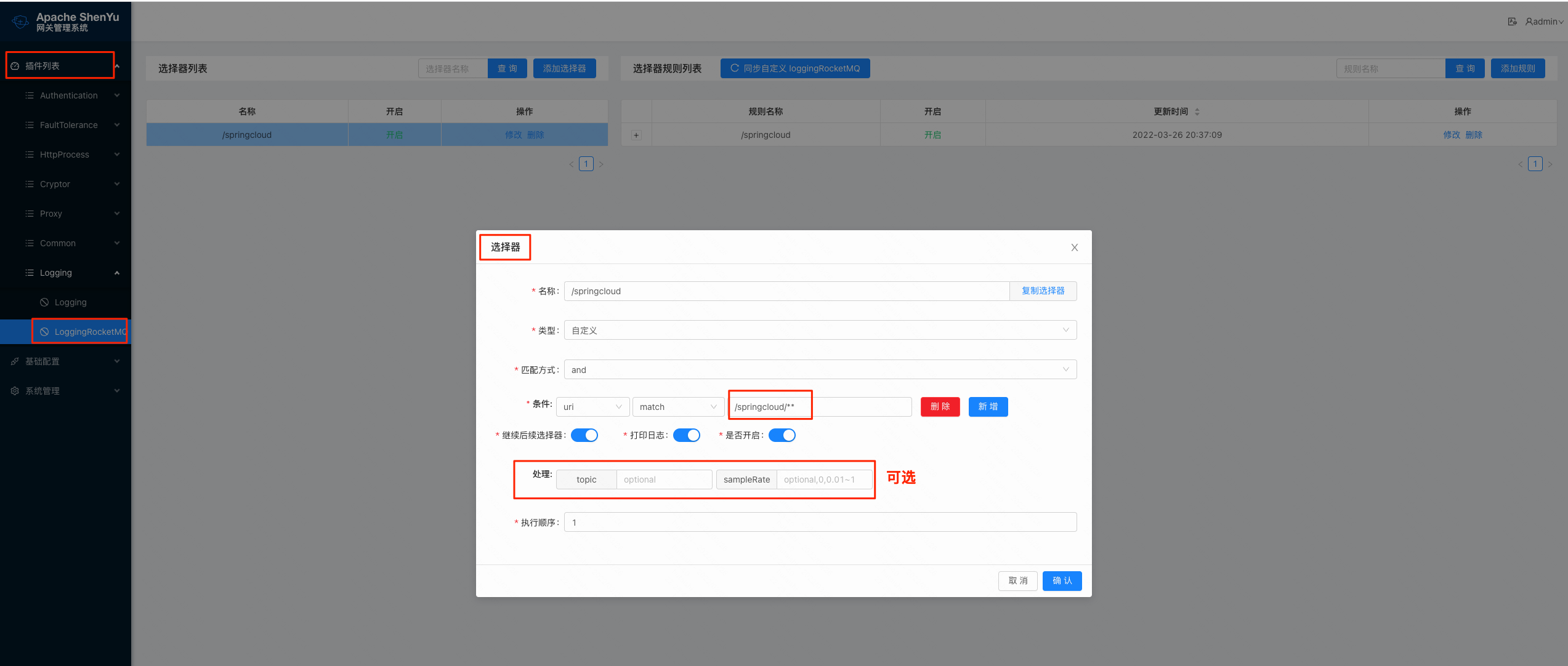
2.6.1.2 选择器配置
- 选择器和规则详细配置,请参考: 选择器和规则管理。
另外有时候一个大网关集群对应多个应用程序(业务),不同应用程序(业务)对应不同的主题,相关隔离,这时候可以按选择器配置不同的主题(可选)和采样率(可选),配置项的含义如上表所示。
操作如下图:
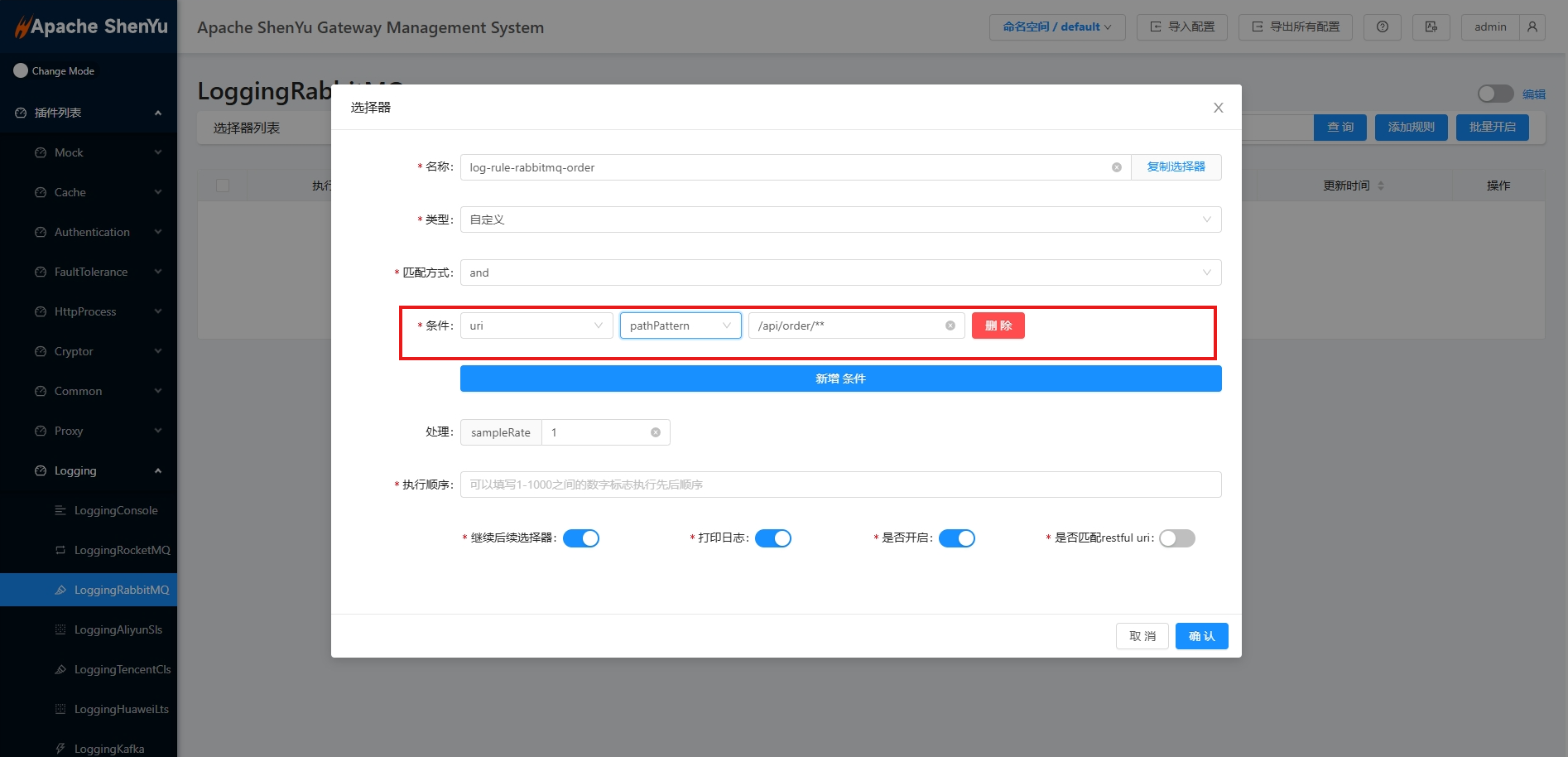
2.6.1.3 规则配置
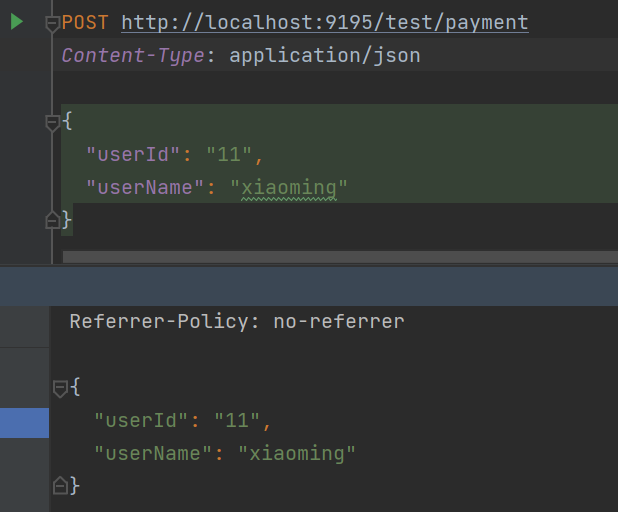
2.6.1.4 请求服务
2.6.1.5 消费以及展示Logging
由于各个日志平台有差异,如存储可用clickhouse,ElasticSearch等待,可视化有自研的或开源的Grafana、Kibana等。
Logging-RabbitMQ插件利用RabbitMQ进行生产和消费解耦,同时以json格式输出日志,消费和可视化需要用户结合自身情况选择不同的技术栈来实现。
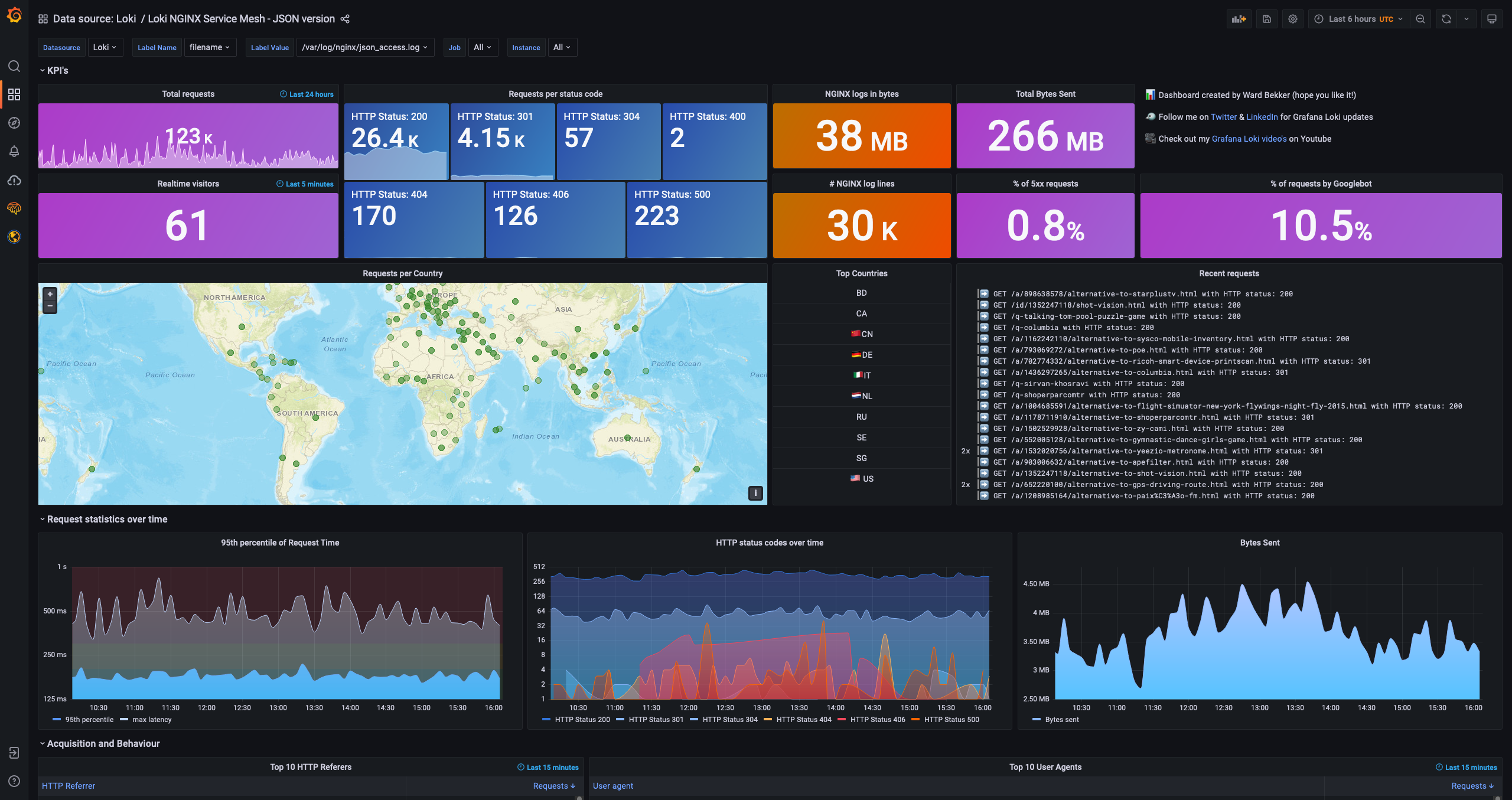
2.6.1.6 面板展示
用户可根据自身情况选择可视化实现。
下面展示下 Grafana 效果:
Grafana沙盒体验
3. 如何禁用插件
- 在
shenyu-admin--> 基础配置 --> 插件管理-> loggingRabbitMQ ,设置为关闭。